AI-generated synthetic data is changing the game in artificial intelligence and machine learning. For some models, up to 90% of the data used for training AI is made by models, not collected from the real world. According to Gartner, by 2030 the vast majority of data used in training models will be synthetic.
This type of data is a big deal for AI experts. It’s cheaper, grows easily, and doesn’t fall under PII laws in most countries. By making fake data covering many different situations, AI gets better at doing real-world tasks. Plus, it allows for creating images or photos that keep personal info safe, following rules about data privacy.
What is Synthetic Data and How is it Generated?
Synthetic data is a big deal in AI and machine learning. It’s text, video, voice, or other materials generated by large language models or visual generative models, such as Stable Diffusion. To put it very simply, this technique makes fake data that looks like something you’d find in the real world.
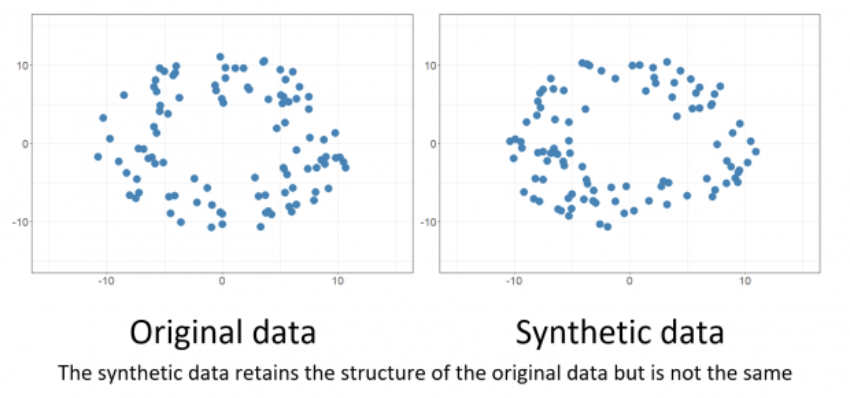
Defining Synthetic Data
Synthetic data comes from algorithms that study real data and reflect real-world scenarios with the help of mathematical and statistical calculations. These algorithms look at the stats and patterns in the world and try to recreate them. So, if you’ve heard that tools like ChatGPT, Gemini, and so on, are just clever word guessers – it’s a largely true statement.
These algorithms generate data that looks similar to real patterns, sometimes indistinguishable. Synthetic data is familiar but doesn’t directly reflect any real people, locations, voices, etc.
Generative Models for Synthetic Data Creation
Generative models like GANs and variational autoencoders are key in making synthetic data. These models learn the real data’s structure and make new data that looks real. They’re great for making data that’s useful for many things.
For example, Ford uses synthetic data made with gaming engines and GANs to train AI models. American Express also uses GANs to make fake data for better fraud detection.
Simulating Data Based on Predefined Rules and Parameters
A common way to make synthetic data is by using simulation software and rules. Developers can set what they want the data to look like. This lets them make data that’s just right for their needs.
BMW uses this in NVIDIA Omniverse to make virtual factories. They work on making assembly lines better with robots. Amazon Robotics trains their robots with simulated data to recognize different packages.
Synthetic data is getting more popular because it solves many challenges with real data. It’s inexpensive, fast to produce, easy to structure, and often comes pre-labeled for computer vision and various machine learning models.
Advantages of Using Synthetic Data in AI and Machine Learning
The best selling point of synthetic data is its scalability. It can be made in huge amounts, which is great for training. This lets companies create lots of data for testing and training their models.
This also comes with high data diversity. In other words, synthetic data lets businesses test models in different scenarios, making them more reliable by addressing biases. It’s especially useful in fields like healthcare and finance where real data is hard to get due to regulations and other restrictions.
In other words, synthetic data can also simulate rare events, helping prepare AI for edge cases and exceptions.
Data quality control is a major part of synthetic data. Researchers can tweak the data to improve model performance. Synthetic data comes with perfect annotation, automatically labeling each object in a scene during creation. Some models are advanced enough to create synthetic LiDAR and other 3d environments.
Challenges in Generating High-Quality Synthetic Data
Creating synthetic data that truly reflects real-world situations is tough. It’s key to make sure the data is accurate and captures the real world’s complexity. This avoids biases or mistakes in AI models. Synthetic data faces a few issues:
- Lack of nuance. Creating complex and rich synthetic data is complicated and specialized scenarios in manufacturing, robotics, and so on, require training custom generative AI to even consider the possibility of using this kind of data for training.
- Inherited algorithmic bias. If your generative AI has biases like misrepresenting specific types of objects, people, and so on, this will be present in all synthetic data you create.
- Model regression. After a large number of generations, generative models often ‘drift’ into producing homogenous images of lower quality. This is why real data and human supervision are important. We discussed this in a different article.
Replicating Real-World Scenarios Accurately
It’s tough to make synthetic data that truly reflects real life. Real data often has complex patterns and things that are hard to copy. Methods like distribution-based approaches try to mimic the original data’s spread through math formulas.
Advanced models like VAEs and GANs are getting better at capturing complex data and making realistic samples. These models learn the data’s structure and can make new data that looks like the real thing.
Maintaining Data Diversity
Keeping synthetic data diverse is key for AI models to work well in real life. Generators must aim for a mix of different groups and factors to avoid bias and keep AI fair and balanced. Techniques like oversampling and using expert knowledge can boost diversity. This leads to better AI performance and less bias.
This is where human experts come into the picture – human-in-the-loop techniques are incredibly important for keeping synthetic datasets accurate and representative, as well as avoiding drift.
Synthetic Data vs Real-World Data: Which is Better?
Choosing between synthetic and real-world data for AI and machine learning projects depends on the project’s needs. Both types have their pros and cons. It’s important to think about these carefully.
Real-world data is true to life and captures real-world complexities. It’s great for tasks needing high accuracy. But, getting certain data can be hard and expensive, for example, small manufacturers simply can’t afford to create vast datasets of all possible product defects – but they can use a few samples to generate thousands of variations with ease.
Synthetic data is flexible and easy to control. It lets you test and train models precisely. It can create rare events for AI training, solving real data scarcity issues. You can change simulation settings as needed.
But, synthetic data has its own challenges. It might lead to biased results and definitely requires extra human supervision. Consider implementing clear rules for data governance.
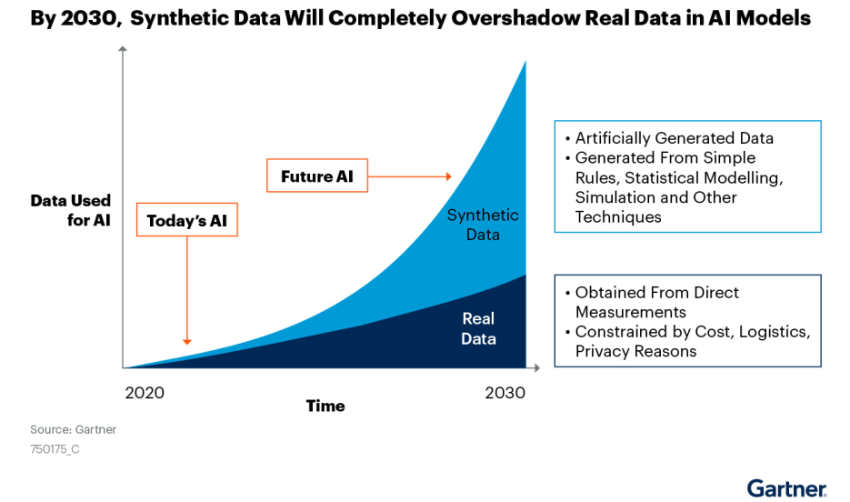
The choice between synthetic and real data depends on the project’s needs. Often, using both types together works best. Gartner, for example, suggests that real-world data will continue being a large part of training, but the use of synthetic data will shoot up exponentially:
Applications of Synthetic Data in Various Industries
Synthetic data is changing the game in many fields. It lets companies share data safely, speeds up innovation, and makes AI and machine learning more accurate. This tech is used in healthcare, automotive, retail, and finance, solving big problems and opening new doors for smart decision-making.
Healthcare
In healthcare, synthetic data helps improve patient care while keeping patient info private. By using fake medical data, doctors can train AI for things like medical imaging analysis without risking patient privacy. Big pharma company Roche uses synthetic data to speed up finding new drugs.
It also lets doctors practice and plan treatments without sharing real patient info21. This safe sharing helps teams work better together and makes data sharing smoother21.
Automotive
The car industry is also seeing big benefits from synthetic data, especially with self-driving cars. Waymo, for example, uses it to train autonomous vehicles. This way, they can train their cars fast without needing lots of real-world data.
It lets car makers test their self-driving cars in simulated worlds and environments. This helps them try out different driving situations before hitting the road.
Retail and Finance
Retailers are using synthetic data to better manage stock and understand what customers want. By creating dummy customer data, they can make smarter choices to improve their stores and customer service. For example, Amazon uses synthetic data to train its cashier-less stores.
In finance, synthetic data is key for spotting fraud and assessing risks. Companies like American Express and J.P. Morgan use it to great effect. It helps them test new ways to catch fraud in unique scenarios.
By using synthetic data, banks can follow strict privacy rules and still analyze data to find trends.
Overall, synthetic data speeds up innovation, keeps data private, and helps make accurate predictions. It’s set to change how we make decisions across many verticals.
Future of Synthetic Data in AI and Machine Learning
The future of synthetic data in AI and machine learning looks bright. With new tech in generative models and simulation, synthetic data will be key for growth in many fields.
Emerging Trends: Federated Learning and Differential Privacy
New trends like federated learning and differential privacy will make synthetic data even more useful for keeping AI safe and private. Federated learning lets different groups train models together without sharing all their data, lowering privacy risks. Adding synthetic data to this makes it easier to use diverse data safely.
Differential privacy adds noise to data to protect privacy while still letting us learn from different scenarios. When used with synthetic data, it keeps the data’s true nature without sharing any personal info at all.
Together, synthetic data, federated learning, and differential privacy open new doors for many safe AI applications.
As AI grows, it will need more diverse and quality data for training. Synthetic data is a smart and affordable way to do just that! However, there are still a few things to keep in mind while using it:
Best Practices for Generating and Using Synthetic Data
Synthetic data requires careful validation – human supervision guards your models against creating irrelevant junk data that could hurt the capabilities of your models. It keeps the data accurate and reliable.
It’s also vital to keep the data diverse. By adding different variations and ensuring a balanced mix, developers can create thorough datasets. This helps avoid bias and overfitting, or your model being dysfunctional outside of training data. This is especially true for imbalanced training data, where most instances belong to only one class.
For high-quality synthetic data, the right generation techniques are key. You can pick from methods like decision trees, deep learning techniques, and iterative proportional, based on your model’s needs. Data scientists often use libraries like Scikit-learn, SymPy, and Pydbgen to generate synthetic data for machine learning tasks.
Lastly, to establish trust in synthetic data, implement a thorough QA process. Check your synthetic samples against real-world benchmarks. If you’re not sure where to start, work with a specialized vendor like Keymakr to find the best fit for your training dataset needs.
What’s Next?
The synthetic data revolution is changing how we use AI and machine learning. It lets developers make high-quality, diverse datasets while keeping things private and pushing AI forward. By using advanced models and simulation, synthetic data can mimic real-world situations well. You get stronger models for a better price, opening doors to exciting solutions.
This tech is incredibly useful in healthcare, where sharing patient data is hard because of regulations like HIPAA or various PII laws. It lets researchers use synthetic data to solve problems creatively without going through a complicated process of acquiring anonymized data.
Synthetic data, however, is not a silver bullet. Gartner’s 2023 hype cycle placed it sliding down the ‘Peak of Inflated Expectations’:
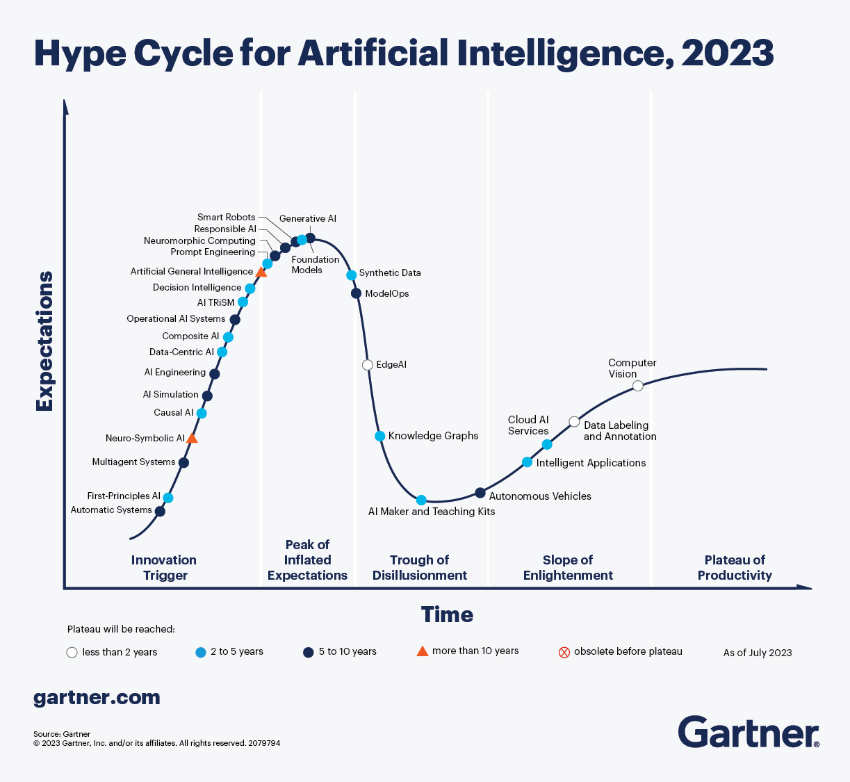
We are yet to develop the most powerful ways of using this technology and are already coming to understand that it requires humans for careful supervision and QA. Going forward, the future of synthetic data is in the hands of data governance techniques and finding the right ways to loop human specialists into the validation and augmentation process.
By using synthetic data responsibly, companies can become more flexible, improve models, and stay on top of the upcoming AI regulations. Most AI developers would do well by getting ahead of the trend and focusing on checks and balances over generative AI, going past the early hype of cheap and easily available data.
